Generates an article for you using OpenAI API in Java and EdgeChain.
Consider you have to write an article about Global Warming: Normally you have to find information about it in various websites, but this particular model helps you in generating the article by just providing the title of the article. EdgeChain is a streamlined solution for developing GenAI applications, offering simplicity through a single script file and jsonnet file setup. It emphasizes versioning for prompts, automatic parallelism across various processors, fault tolerance, and scalability, making it a robust choice for chain-of-thought applications with extensive API integration and data sets. While LangChain primarily focuses on a specific set of principles, EdgeChain takes a unique stance, emphasizing declarative prompt and chain orchestration as pivotal components of its architecture. To delve deeper into EdgeChain and explore its capabilities, you can refer to GitHub repository https://github.com/arakoodev/edgechains#why-do-you-need-declarative-prompt--chain-orchestration-. This platform offers a comprehensive view of EdgeChains' vision and how it differentiates itself from LangChain.
Pre Requisites
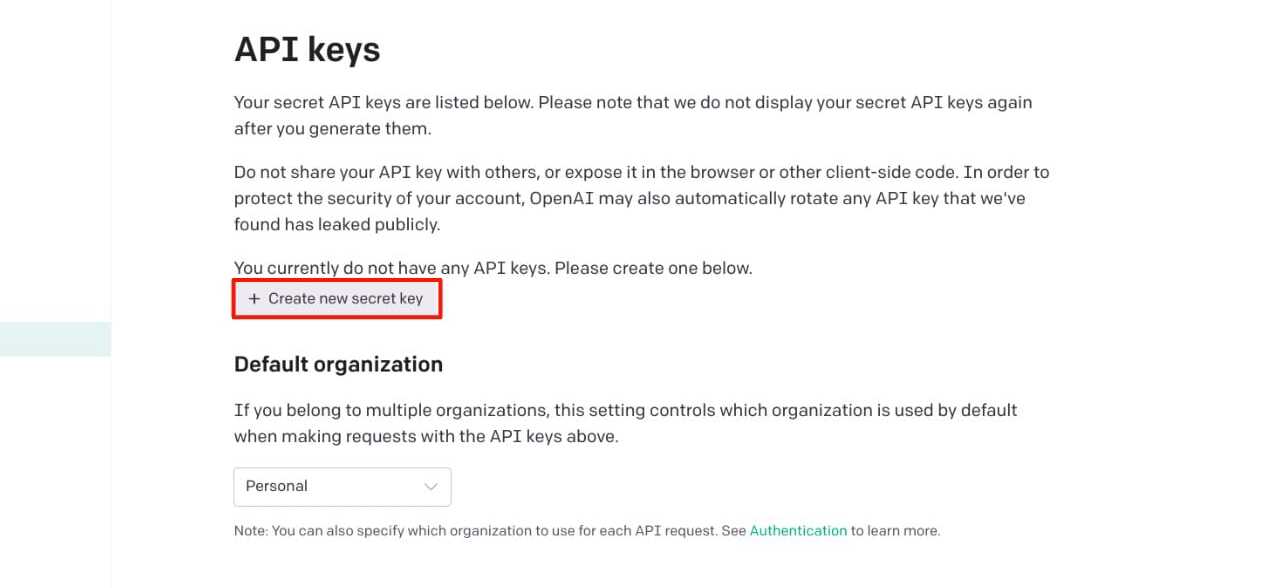
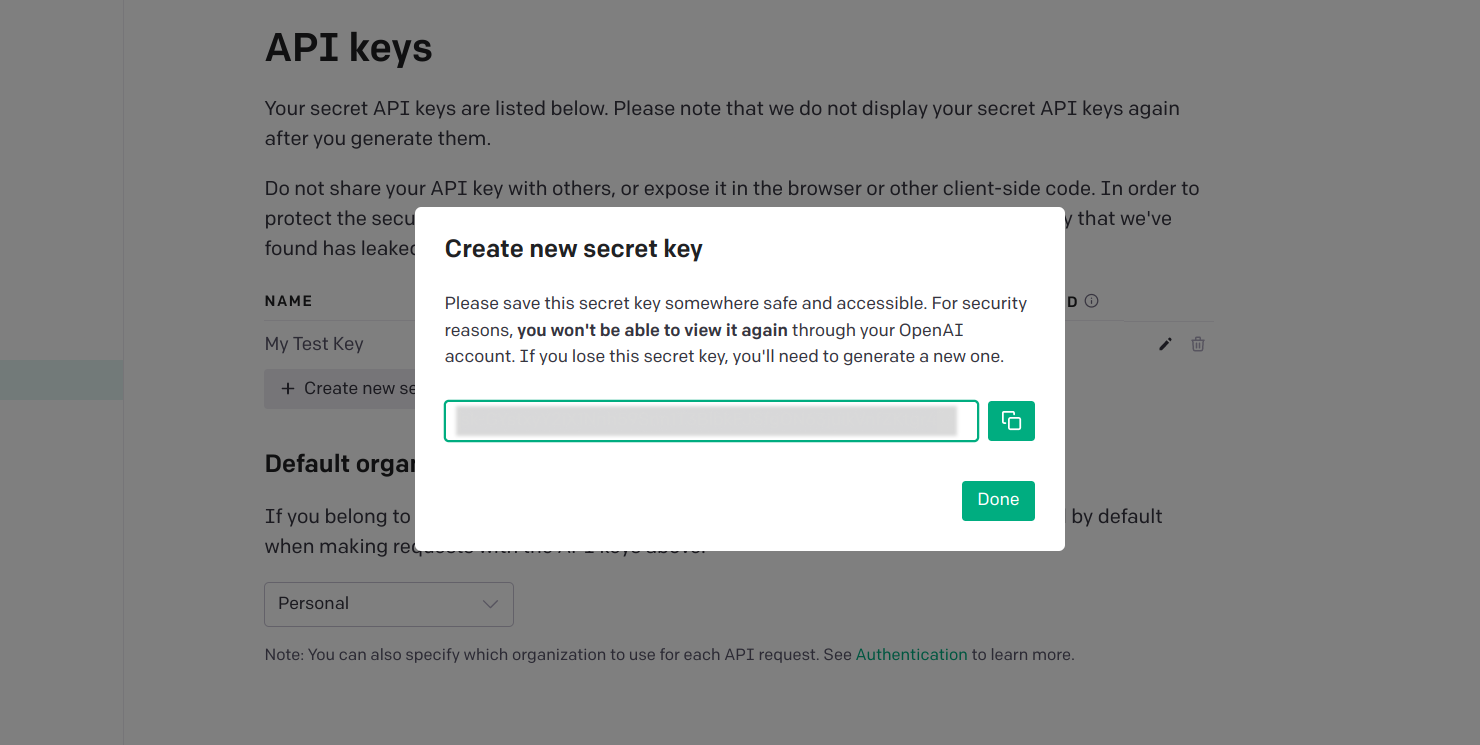
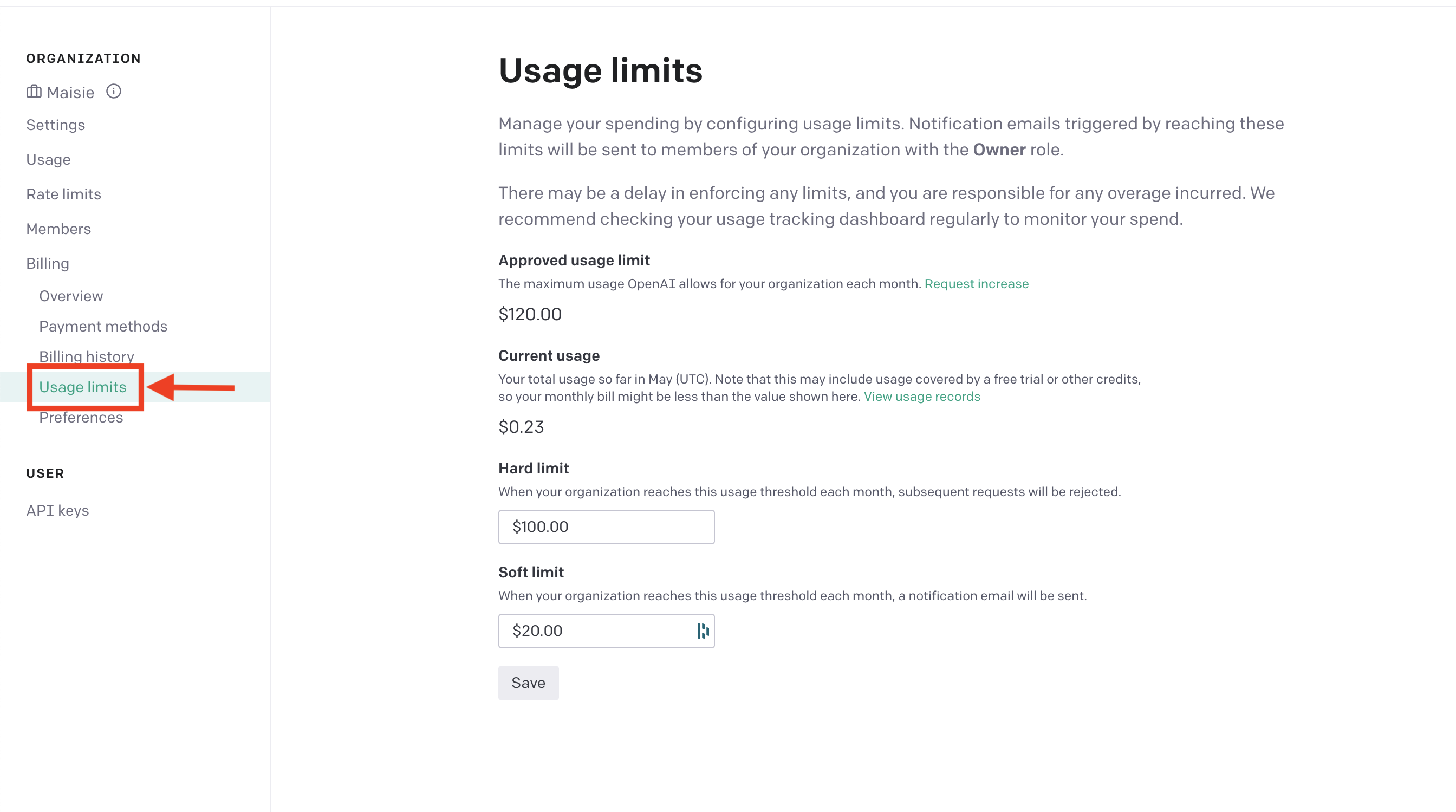
- You need to make an account in OpenAI, Postgres so that from there you can retrieve the AUTH key, org id and etc. which are needed for the code.
- You need to download the edgechains jar file from this url https://github.com/arakoodev/EdgeChains/releases.
- Download the .java and .jsonnet file and put them in the same folder.
- In the code according to the folder structure you have to write about the path.
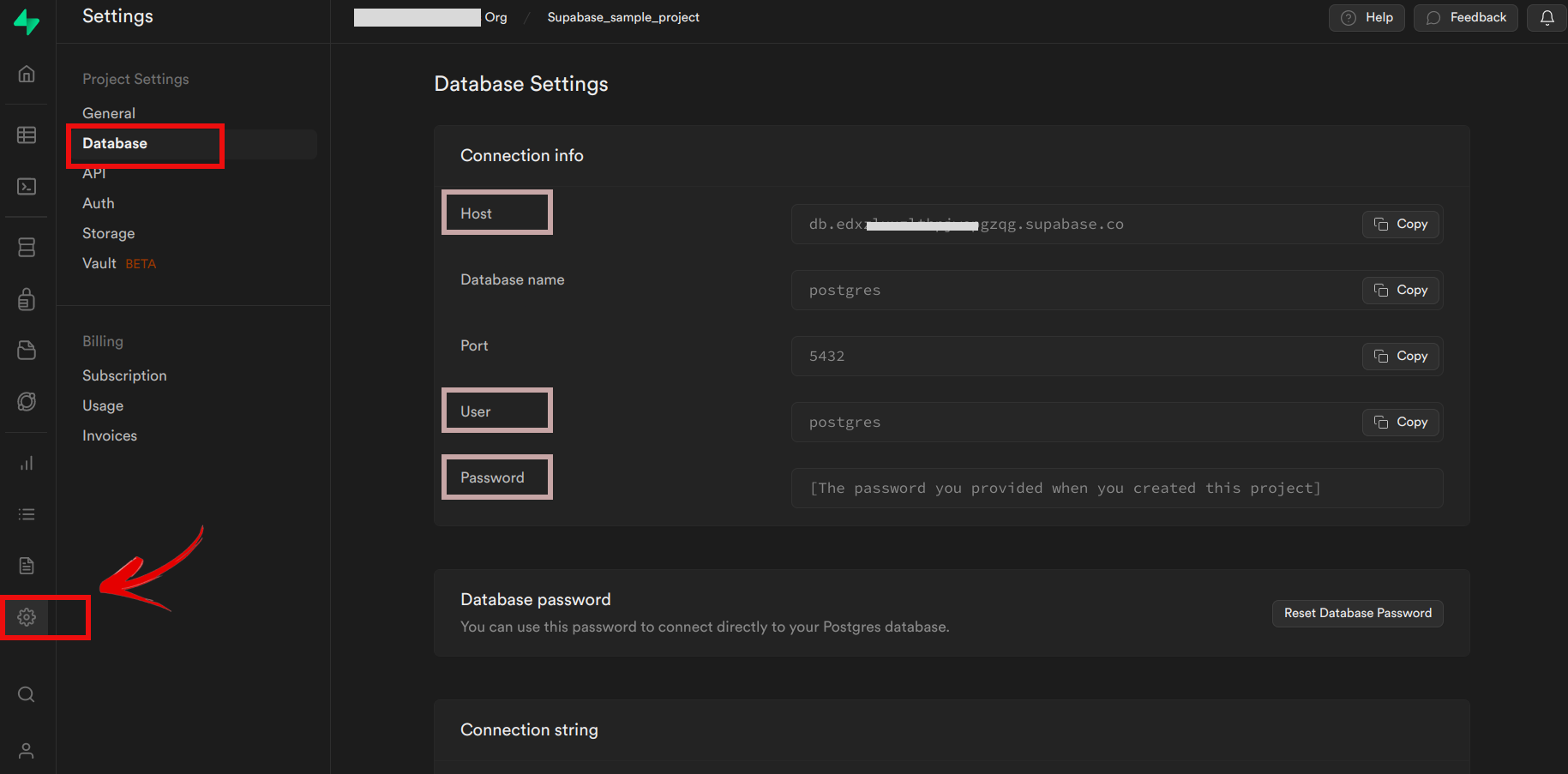
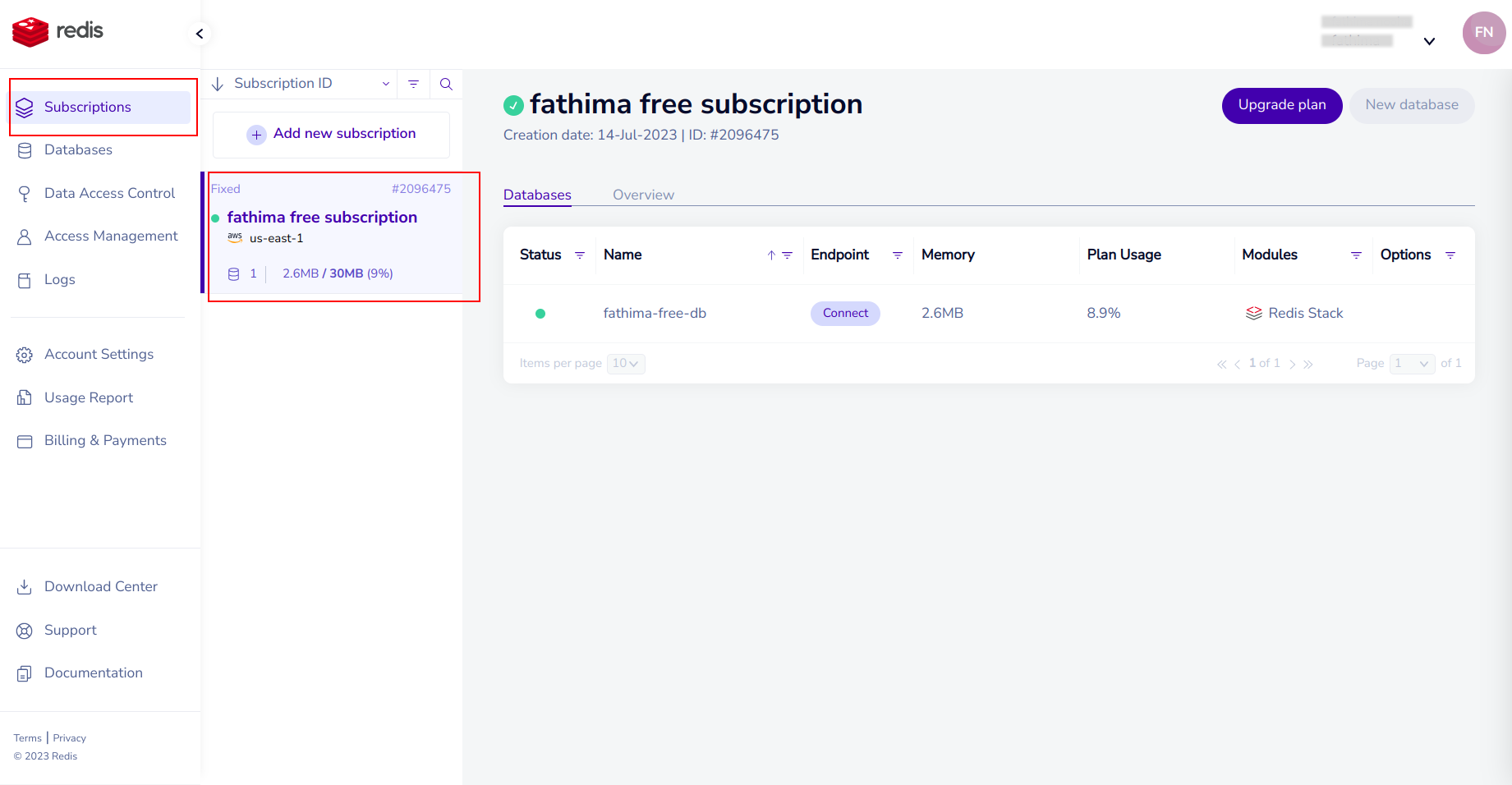
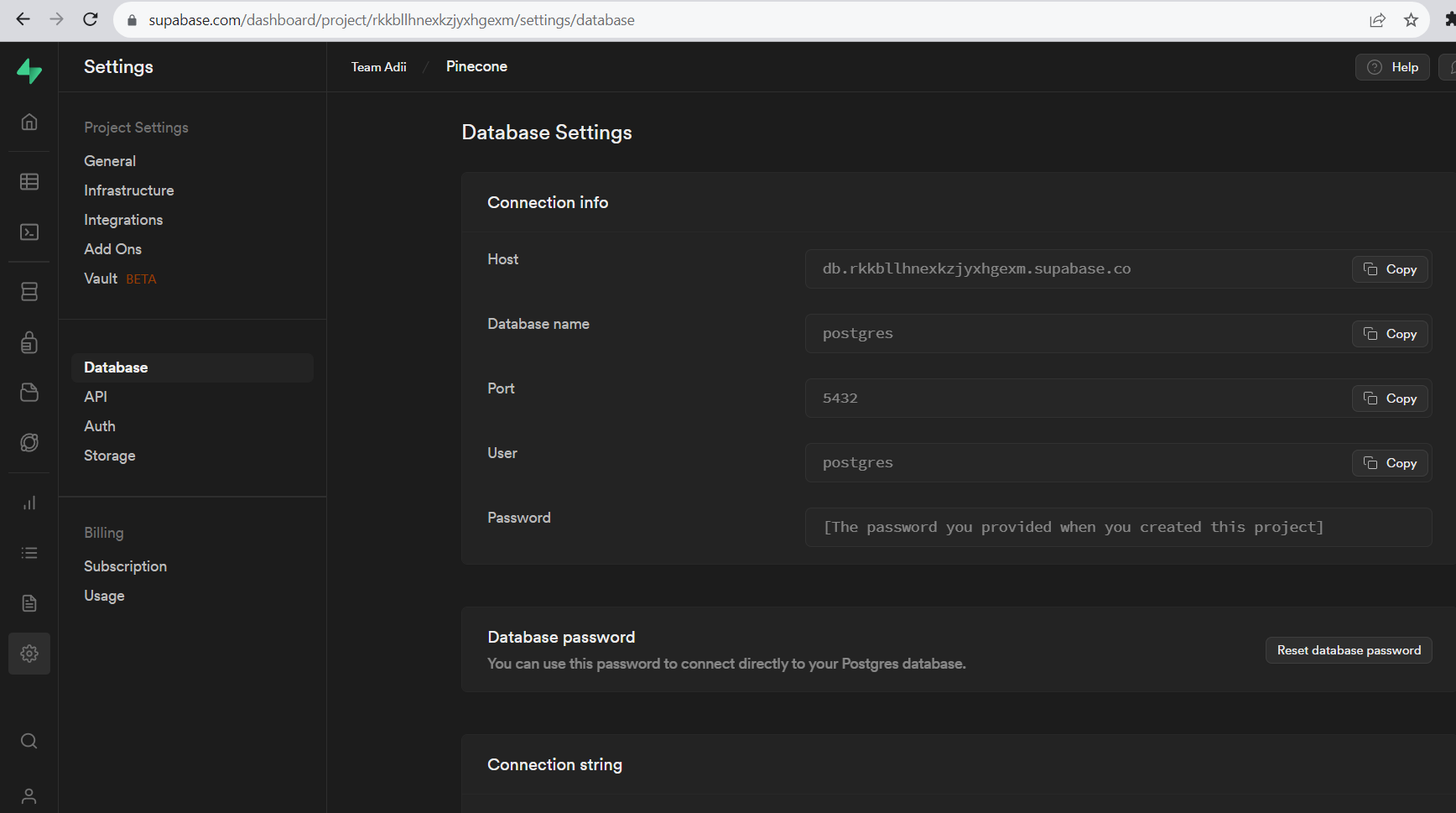
Configuration of the Database
- Go to the Supabase website (https://supabase.io) and sign up for an account.
- Create a new Project by clicking the “New Project” button.
- Configure your project settings including the project name, region, and the plan.
- Once your project is created, you’ll be directed to the project dashboard.
- Click the “Create Database” button to create a new PostgreSQL database.
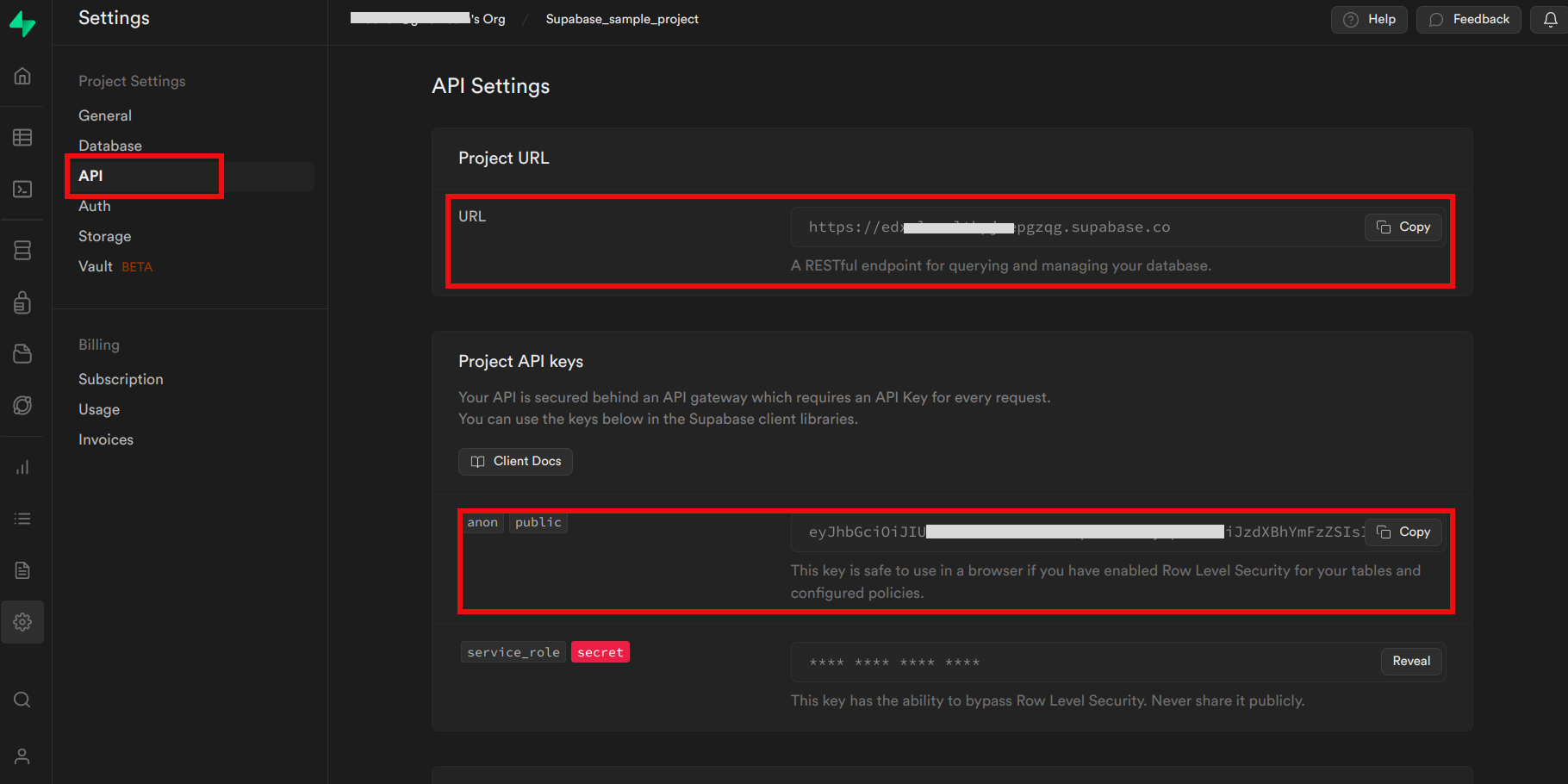
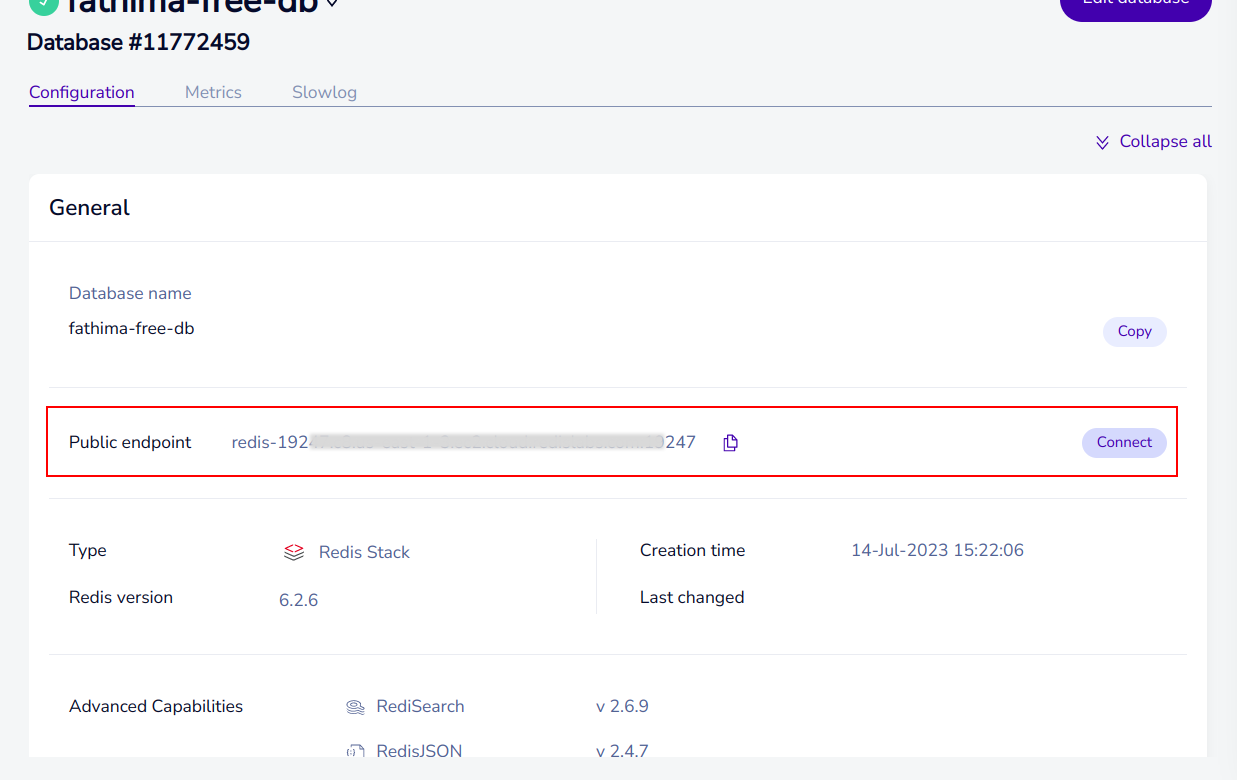
- After the database is created, you can access its credentials, including the database URL, API URL and service role key.
Explanation of the Code
Load the edgechains package.
Import the OPENAI_Chat_Completion API. Here we have to import the static constants from other classes. These classes are of OpenAI.
Import the Spring Framework related classes and annotations.
The code relies on external libraries and dependencies, such as
com.edgechain.libandio.reactivex.rxjava3.These dependencies provide additional functionality and utilities for the code.Classes such as
OpenAiEndpoint,WikiEndpoint,ArkRequest, andCompletionRequestare used to interact with specific endpoints or APIs, such as OpenAI and Wikipedia.RxJava and Retry Logic: The code uses RxJava and includes classes like
ExponentialDelayandEdgeChain.These are used for implementing retry logic and handling asynchronous operations.The code includes a constant
OPENAI_CHAT_COMPLETION_API, which represents the endpoint for OpenAI chat completion.A class named
WikiExampleis present that includes several static variables and aJsonnetLoaderinstance. Here's an explanation of the that:Static Variables:
OPENAI_AUTH_KEY: This variable represents the OpenAI authentication key. It is a string that should be replaced with your actual OpenAI authentication key.OPENAI_ORG_ID: This variable represents the OpenAI organization ID. It is a string that should be replaced with your actual OpenAI organization ID.gpt3Endpoint: This variable is an instance of theOpenAiEndpointclass, which is used to communicate with OpenAI services.gpt3StreamEndpoint: This variable is another instance of theOpenAiEndpointclass, which is likely used for streaming communication with OpenAI services.wikiEndpoint: This variable is an instance of theWikiEndpointclass, which is used to communicate with the Wikipedia API.
JsonnetLoader
- `loader`: This variable is an instance of the `JsonnetLoader` class, which is used to load and process Jsonnet files.
- `FileJsonnetLoader`: This class is a specific implementation of the `JsonnetLoader` interface that loads Jsonnet files from the file system.
- The `FileJsonnetLoader` constructor takes three arguments:
- The first argument represents the probability (in percentage) of executing the first file (`./wiki1.jsonnet`). In this case, there is a 70% chance of executing `./wiki1.jsonnet`.
- The second argument is the path to the first Jsonnet file (`./wiki1.jsonnet`).
- The third argument is the path to the second Jsonnet file (`./wiki2.jsonnet`).
The purpose of this code is to create an instance of FileJsonnetLoader that loads Jsonnet files with a certain probability. Depending on the probability, either ./wiki1.jsonnet or ./wiki2.jsonnet will be executed.
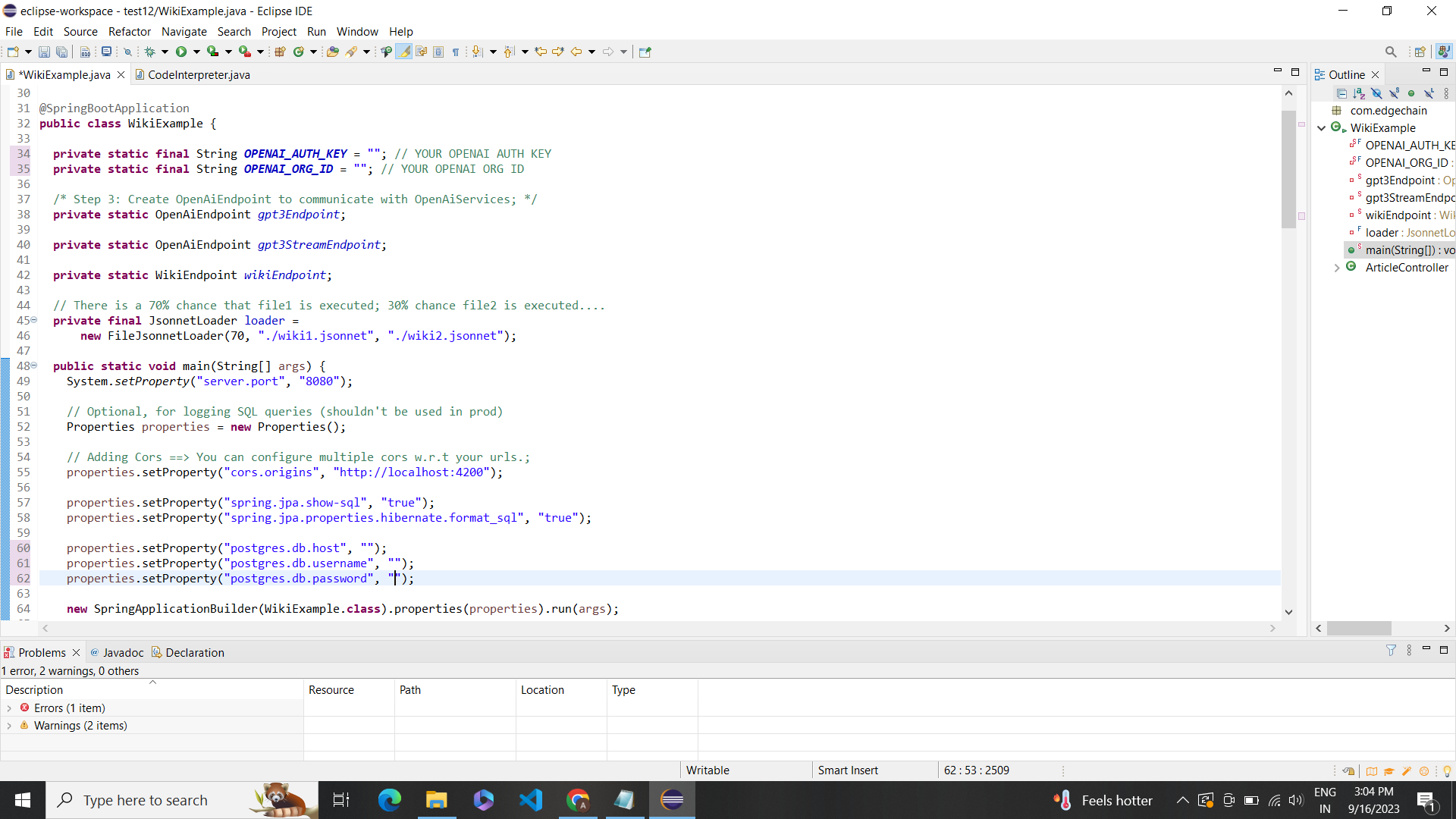
The main method is the entry point of the application.
Setting Server Port:System.setProperty("server.port", "8080"): This line sets the server port to 8080. It configures the application to listen on port 8080 for incoming requests.
Configuring Properties:Properties properties = new Properties(): This line creates a new instance of thePropertiesclass, which is used to store key-value pairs of configuration properties.properties.setProperty("cors.origins", "http://localhost:4200"): This line sets the CORS (Cross-Origin Resource Sharing) origins property to allow requests fromhttp://localhost:4200. CORS is used to control access to resources from different origins.
Configuring JPA and Hibernate Properties:properties.setProperty("spring.jpa.show-sql", "true"): This line sets the property to show SQL queries executed by JPA (Java Persistence API).properties.setProperty("spring.jpa.properties.hibernate.format_sql", "true"): This line sets the property to format the SQL queries executed by Hibernate.
Configuring PostgreSQL Database Properties:properties.setProperty("postgres.db.host", "jdbc:postgresql://db.rkkbllhnexkzjyxhgexm.supabase.co:5432/postgres"): This line sets the PostgreSQL database host URL.properties.setProperty("postgres.db.username", "postgres"): This line sets the username for the PostgreSQL database.properties.setProperty("postgres.db.password", "jtGhg7?JLhUF$fK"): This line sets the password for the PostgreSQL database.
Starting the Spring Boot Application:new SpringApplicationBuilder(WikiExample.class).properties(properties).run(args): This line creates a new instance ofSpringApplicationBuilderwith theWikiExampleclass as the main application class. It sets the configured properties and runs the Spring Boot application.
Initializing Endpoints:
- `wikiEndpoint = new WikiEndpoint()`: This line creates an instance of the `WikiEndpoint` class, which is used to communicate with the Wikipedia API.
- `gpt3Endpoint = new OpenAiEndpoint(...)`: This line creates an instance of the `OpenAiEndpoint` class, which is used to communicate with OpenAI services. It sets various parameters such as the OpenAI chat completion API, authentication key, organization ID, model, temperature, and delay.
- `gpt3StreamEndpoint = new OpenAiEndpoint(...)`: This line creates another instance of the `OpenAiEndpoint` class, which is likely used for streaming communication with OpenAI services. It sets similar parameters as the `gpt3Endpoint`, but with an additional flag for streaming.
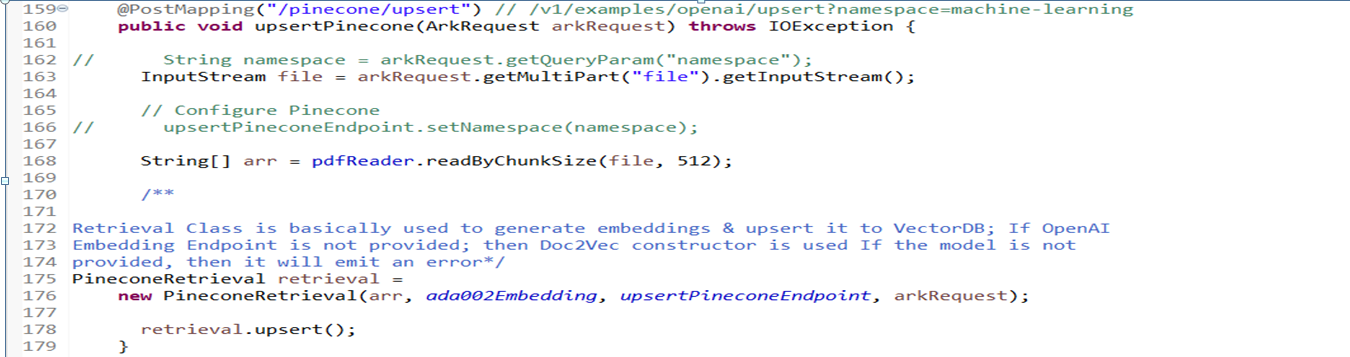
Article Writer Controller
- It is a
RestControllerclass namedArticleControllerthat handles HTTP GET requests for the/articleendpoint. Here's an explanation of the code within the class:
@RestControllerAnnotation:- This annotation is used to indicate that the class is a REST controller, which means it handles HTTP requests and returns the response in a RESTful manner.
@GetMapping("/article")Annotation:- This annotation is used to map the HTTP GET requests with the
/articleendpoint to thegenerateArticlemethod.
- This annotation is used to map the HTTP GET requests with the
generateArticleMethod:- This method is responsible for generating an article based on the provided query parameter.
- It takes an
ArkRequestobject as a parameter, which is likely a custom request object that contains query parameters. - The method throws an
Exceptionif any error occurs during the generation process.
Generating the Prompt:
- The method prepares a prompt for the article generation by concatenating the string "Write an article about " with the value of the
titlequery parameter from thearkRequestobject.
- The method prepares a prompt for the article generation by concatenating the string "Write an article about " with the value of the
Sending a Request to the OpenAI API:
- The method uses the
gpt3Endpointinstance (which is an instance of theOpenAiEndpointclass) to send a request to the OpenAI API for generating the article. - It uses the
chatCompletionmethod of thegpt3Endpointto perform the chat completion. - The
chatCompletionmethod takes the prompt, a chat model name ("React-Chain"), and thearkRequestobject as parameters. - The generated article is stored in the
gptrevariable.
- The method uses the
Returning the Generated Article:
- The method returns the generated article as a response to the HTTP GET request.
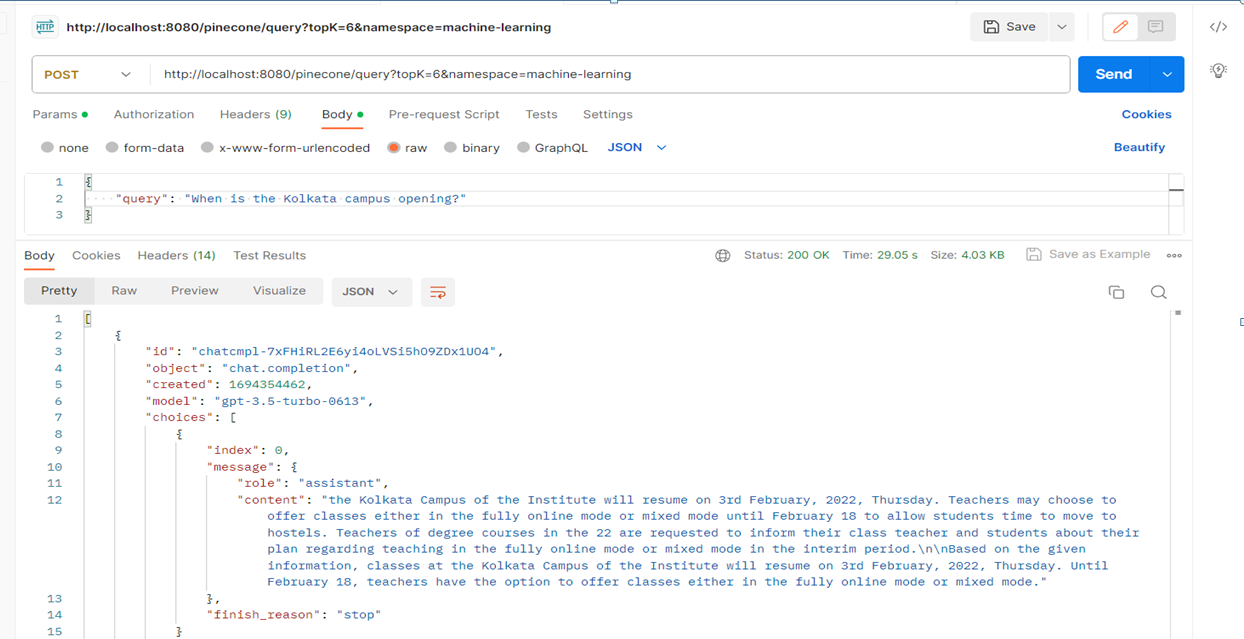
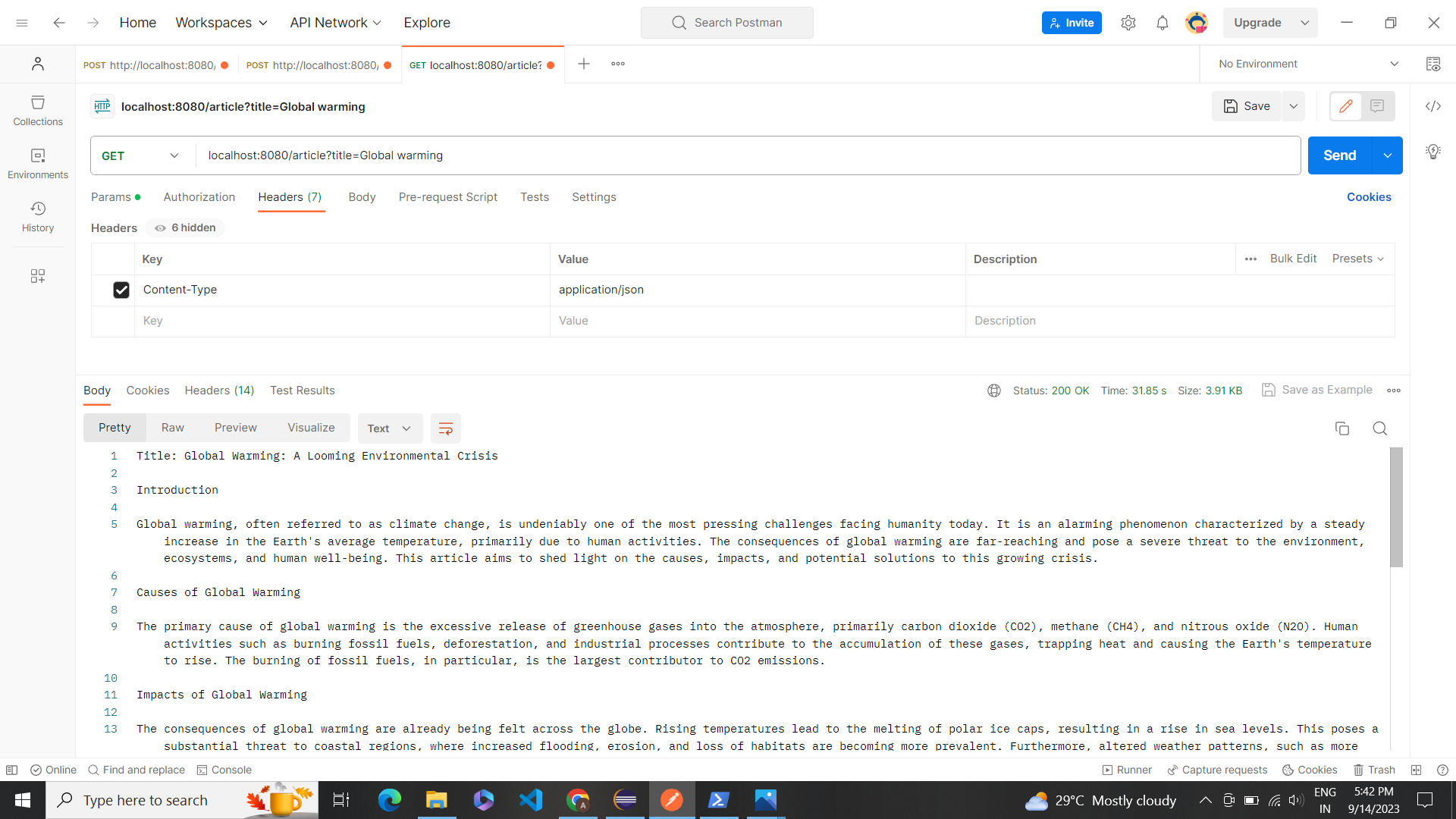
Postman Testing
After all this we will be using the postman to test and give the requests for the same in the following manner: Title
- Description: Perform a query to retrieve results from Open AI.
- Method: POST
- URL:localhost:8080/article?title=Global warming
- Headers: Content-Type: application/json
- Body: raw
Full Working Code
package com.edgechain;
import com.edgechain.lib.endpoint.impl.llm.OpenAiChatEndpoint;
import com.edgechain.lib.endpoint.impl.wiki.WikiEndpoint;
import com.edgechain.lib.jsonnet.JsonnetLoader;
import com.edgechain.lib.jsonnet.impl.FileJsonnetLoader;
import com.edgechain.lib.request.ArkRequest;
import com.edgechain.lib.rxjava.retry.impl.ExponentialDelay;
import com.edgechain.lib.rxjava.transformer.observable.EdgeChain;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import static com.edgechain.lib.constants.EndpointConstants.OPENAI_CHAT_COMPLETION_API;
@SpringBootApplication
public class WikiExample {
private static final String OPENAI_AUTH_KEY = ""; // YOUR OPENAI AUTH KEY
private static final String OPENAI_ORG_ID = ""; // YOUR OPENAI ORG ID
/* Step 3: Create OpenAiEndpoint to communicate with OpenAiServices; */
private static OpenAiChatEndpoint gpt3Endpoint;
private static OpenAiChatEndpoint gpt3StreamEndpoint;
private static WikiEndpoint wikiEndpoint;
// There is a 70% chance that file1 is executed; 30% chance file2 is executed....
private final JsonnetLoader loader =
new FileJsonnetLoader(70, "./wiki1.jsonnet", "./wiki2.jsonnet");
public static void main(String[] args) {
System.setProperty("server.port", "8080");
// Optional, for logging SQL queries (shouldn't be used in prod)
Properties properties = new Properties();
// Adding Cors ==> You can configure multiple cors w.r.t your urls.;
properties.setProperty("cors.origins", "http://localhost:4200");
properties.setProperty("spring.jpa.show-sql", "true");
properties.setProperty("spring.jpa.properties.hibernate.format_sql", "true");
properties.setProperty("postgres.db.host", "");
properties.setProperty("postgres.db.username", "");
properties.setProperty("postgres.db.password", "");
new SpringApplicationBuilder(WikiExample.class).properties(properties).run(args);
wikiEndpoint = new WikiEndpoint();
gpt3Endpoint =
new OpenAiChatEndpoint(
OPENAI_CHAT_COMPLETION_API,
OPENAI_AUTH_KEY,
OPENAI_ORG_ID,
"gpt-3.5-turbo",
"user",
0.7,
new ExponentialDelay(3, 5, 2, TimeUnit.SECONDS));
gpt3StreamEndpoint =
new OpenAiChatEndpoint(
OPENAI_CHAT_COMPLETION_API,
OPENAI_AUTH_KEY,
OPENAI_ORG_ID,
"gpt-3.5-turbo",
"user",
0.7,
true,
new ExponentialDelay(3, 5, 2, TimeUnit.SECONDS));
}
@RestController
public class ArticleController {
@GetMapping("/article")
public String generateArticle(ArkRequest arkRequest) throws Exception {
// Prepare the prompt
String prompt = "Write an article about " + arkRequest.getQueryParam("title") + ".";
// Use the OpenAiService to send a request to the OpenAI API
// GPT-3 model is used with the provided prompt, max tokens is set to 500 for the article length
// and temperature is set to 0.7 which is a good balance between randomness and consistency
// Echo is set to true to include the prompt in the response
/*CompletionRequest completionRequest = CompletionRequest.builder()
.prompt(prompt)
.model("gpt-3.5-turbo")
.maxTokens(500)
.temperature(0.7)
//.echo(true)
.build();*/
String gptre=new EdgeChain<>(gpt3Endpoint.chatCompletion(prompt, "React-Chain", arkRequest))
.get()
.getChoices()
.get(0)
.getMessage()
.getContent();
// Send the request
//ChatCompletionResponse response = gpt3Endpoint.chat(completionRequest);
//Observable<ChatCompletionResponse> response = gpt3Endpoint.chatCompletion(completionRequest.getPrompt(), "", arkRequest);
// Extract the generated text from the response
//String generatedArticle = response.getChoices().get(0).getGeneratedText();
//return response.blockingFirst().getChoices().get(0).toString();
return gptre;
// Return the generated article
// return generatedArticle;
}
}
}
JSONnet for the Code
Data is at the heart of nearly every aspect of technology. Whether you're configuring software, managing infrastructure, or exchanging information between systems, having a clean and efficient way to structure and manipulate data is essential. This is where JSONnet steps in as a valuable tool.
JSONnet is a versatile and human-friendly programming language designed for one primary purpose: simplifying the way we work with structured data. At its core, JSONnet takes the familiar concept of JSON (JavaScript Object Notation), a widely-used format for data interchange, and elevates it to a whole new level of flexibility and expressiveness. It has a declarative way of defining and describing the prompts and chains. The JSONnet for the above code
local keepMaxTokens = payload.keepMaxTokens;
local maxTokens = if keepMaxTokens == "true" then payload.maxTokens else 5120;
local preset = |||
You are a Summary Generator Bot. For any question other than summarizing the data, you should tell that you cannot answer it.
You should detect the language and the characters the user is writing in, and reply in the same character set and language.
You should follow the following template while answering the user:
```
1. <POINT_1> - <DESCRIPTION_1>
2. <POINT_2> - <DESCRIPTION_2>
...
```
Now, given the data, create a 5-bullet point summary of:
|||;
local keepContext = payload.keepContext;
local context = if keepContext == "true" then payload.context else "";
local prompt = std.join("\n", [preset, context]);
{
"maxTokens": maxTokens,
"typeOfKeepContext": xtr.type(keepContext),
"preset" : preset,
"context": context,
"prompt": if(std.length(prompt) > xtr.parseNum(maxTokens)) then std.substr(prompt, 0, xtr.parseNum(maxTokens)) else prompt
}
- KeepMaxTokens and maxTokens - These are used to determine the maximum number of the tokens that will be considered while generating the article.
- preset- This is a string that contains the instructions. Here it tells the bot that it should only answer questions pertaining to giving the summary of the data and it should detect the language and character set of the user's input and respond in the same language and character set ,it kind of gives you the structure of its responses.
- keepContext and context -Used to determine whether the bot should consider the context from the payload when generating the article
- prompt -It is here where the context and preset are combined to create the final prompt for the bot .If the length of the prompt exceeds the maximum number of the tokens, then the prompt is truncated to fit within the limit.
- The Final object- This is the output of the script. It includes everything.